



The life of every application considerably depends on the data it has access to, how it gets such data, the structure of the data, and other factors. How about the cost of maintaining such an application? The amount spent on an application can go high exponentially if the data is fetched more frequently with each request reaching out to a paid third-party service. Worry no more if you have found yourself in a similar situation. With Redis Cache and other enterprise modules, you can ensure that your applications are performant and cost-efficient. But how can we achieve this with Redis?
First, Redis (Remote Dictionary Server) is an open-source in-memory data structure that can serve as a database, a cache, or a message broker. Let us take a closer look at the term "caching" that Redis offers us. Caching is simply the storing of constantly requested data in a storage location and then accessing the data from such a memory instead of hitting the database each time the data is needed. This practice is the key principle behind Cache implementation in Redis. However, unlike other cache providers that keep the copies of your data in a disk, Redis stores the cached resources in memory thereby reducing latency and improving speed. A typical flow for a cache setup in Redis can be seen in the diagram below.
Now that we have an understanding of caching, it is very important to know how to structure the data that we will be storing and how to retrieve it when needed. Employing the right techniques here will not only make accessing the stored data easier but will also improve the performance, scalability, and network efficiency of our cache system. When it comes to modeling data, Redis offers several options that we can choose from depending on our needs and the complexity of the data.
The data types available in Redis include strings, hashes, lists, sets, bitmaps, sorted sets, hyper logs, and geospatial indexes. However, storing JSON data in a type like string may not be the experience or performance that we want in an application. The reason for this is that to store such data as a string, we have to serialize the data before assigning it as a value to a string key. Also, when we need part of the data, we are compelled to fetch the entire data, deserialize it to get the original JSON object, pick our desired information, and serialize it again before storing it. Quite boring and unnecessarily complex, right? It does not end there. When a single field in the object needs to be updated, the above process is repeated.
To avoid these drawbacks and improve developer experience while working with the cache, Redis created the Redis Stack which adds two components:
- Redis-Stack-Server
- RedisInsight
Depending on your OS(Operating System), there are many options out there to choose from to install redis-stack-server on your machine. For Linux users, you would probably achieve this with the commands:
curl -fsSL https://packages.redis.io/gpg | sudo gpg - dearmor -o /usr/share/keyrings/redis-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg] https://packages.redis.io/deb $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/redis.list
sudo apt-get update
Then,
sudo apt-get install redis-stack-server
The Redis-Stack-Server is the normal Redis that we know but then extended with some additional interesting modules to enable us to store and query our data efficiently. These modules include:
- RedisJSON
- RediSearch
- RedisTimeSeries
- RedisBloom
- RedisGraph
We will come back later and apply some of these modules.
RedisInsight on the other hand is a fully-featured pure desktop virtual tool that enables us to perform GUI and CLI-related operations with the Redis database.
To have an efficient and optimized database or cache in Redis, we need RedisJSON and RedisSearch.
RedisJSON
The module RedisJSON is a newer structure for storing data made available on the redis stack. Before this feature was introduced, we had to serialize a JSON object before storing it as a string in Redis. However, mutating the stored object was kind of difficult and unconventional. The whole data is pulled and deserialized before making the intended modifications and when we are done, we had to reserialize the data before storing it. This increases the number of unnecessary data transfers between Redis and the client application and could also increase the cost of running such an application especially if the services are billed based on the number of requests.
An alternative would have been to use hashes but to maintain optimization, the JSON object captured in hashes should not be deeper than one level. This is usually not the case in real applications.
To achieve speed and simplicity, RedisJSON was born. This enables the developers to store JSON data as a simple Redis key irrespective of the depth of the object. Modifying and accessing RedisJSON fields are much easier and we do not have to retrieve the entire data object. We simply update the field that we want with the new value. This in turn saves us time and network bandwidth.
Let us store our first JSON in the Redis cache with the following steps:
Step 1:
We need to have redis-stack-server installed on our system and we can achieve that by following the official installation guide on how to install Redis stack
Step 2:
Start the installed redis-sack-server from your terminal. I am running a Linux machine but the command for your OS should not be much different. Run the command:
redis-stack-server
You will see a screen similar to the one below.
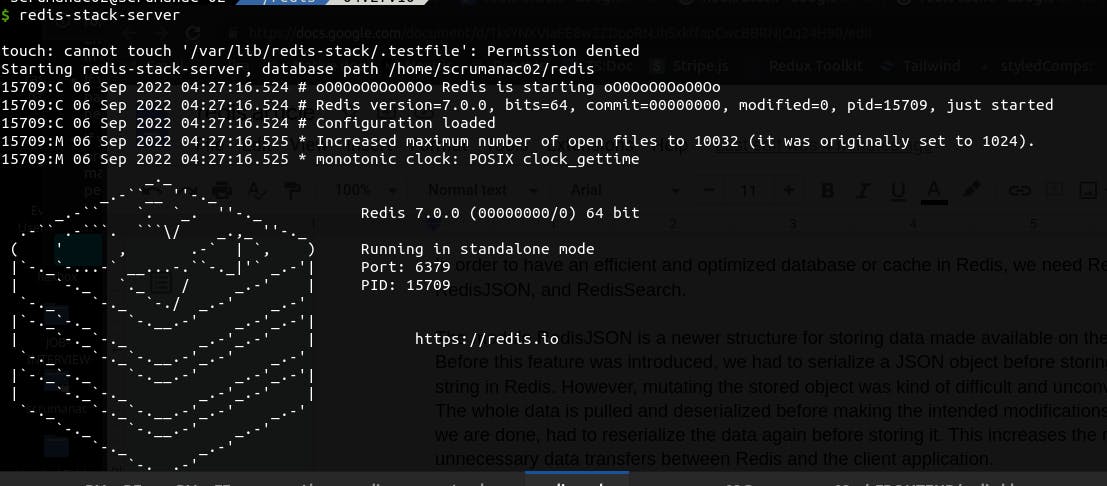
Now, our redis server is ready to accept connections.
Note: Redis by default runs on port 6379 hence you may experience an error if another process is making use of the port.

In that case, you should stop that process and rerun the command above. Alternatively, you can run the command:
sudo service redis-stack-server stop
Step 3:
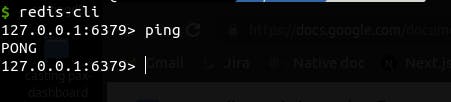
Open another tab on your terminal while leaving the one we opened earlier in the previous step. Start the CLI with the command
redis-cli
We can test that the connection with the redis server is still active by typing PING in the opened CLI. If everything still works fine we should see "PONG" printed on the terminal.
Great!
Step 4:
Let us store a simple JSON object. We will use the command
JSON.SET *key* *path* *value*
For example,
JSON.SET employee:1 $ '{
"name": "Kenneth O.",
"role": "front-end/Mobile Developer",
"skills": ["JavaScript", "ReactJs", "React Native"]
}'
 In the above example,
In the above example,
we use the SET command to tell Redis that we want to store a JSON object.
"employee:1" is our key for referencing the object
we use a special path name "$" to show that we are pointing to the root.
{ "name": "Kenneth O.", "role": "front-end/Mobile Developer", "skills": ["JavaScript", "ReactJs", "React Native"] } is the content of the object that we want to save.
As you may have guessed rightly, the stored object can also be retrieved by calling the GET command. The syntax is quite simple to use too.
JSON.GET **key** **path**
For example, we can get the "role" attribute by running the command
JSON.GET employee:1 $.role

It is also very possible to access nested objects like getting the first element in the "skills" array above. This can be achieved by executing the command below.
JSON.GET employee:1 $.skills[0]
![json-get-skill[0].png](https://cdn.hashnode.com/res/hashnode/image/upload/v1663055538409/i4GnOPAVt.png?auto=compress,format&format=webp) This returns to us "JavaScript". Hmm, much easier and simpler, right?
This returns to us "JavaScript". Hmm, much easier and simpler, right?
Similarly, updating a field in the RedisJSON object is also very convenient. We reference the field that we want to update and the new value replaces the old one. For example, let us change the last member of the "skills" field in our stored object. Currently, we have "React Native" at the last position (index 2).
By executing the command below, we can update the last skill to "CSS"
JSON.SET employee:1 $.skills[2] '"CSS"'

If we try to access the "skills" array attribute again, we will notice that its last item has been updated with our supplied value "CSS"
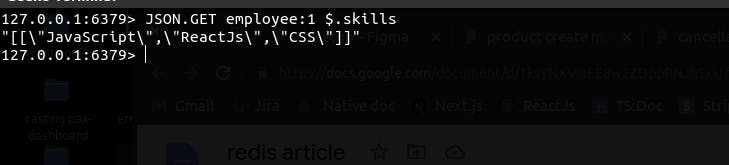 It is that simple!
It is that simple!
So far, we have been requesting to get the different fields of our JSON object but there are times that we may want to see the whole object. This can be achieved by omitting the 'path' argument in our 'GET' command as can be seen below.
JSON.GET employee:1

More detailed documentation on RedisJSON can be seen on the official Redis link More Details on RediJSON
RediSearch
The next Redis feature that we will be looking at is the RediSearch. RediSearch according to the official documentation is " a module that enables querying, secondary indexing, and full-text search on Redis" It provides us with the power to carry out queries with multiple fields, exact phrase matching, numeric filtering, aggregation, and even geo-filtering for our text queries. The RediSearch makes use of inverted and compressed indexes that ensure low and efficient memory usage.
This feature together with the ability to model our data as JSON objects via the RedisJSON that we discussed above, helps to improve the developer experience when working with Redis. With the redis-stack-server we installed earlier, the RediSearch module is made available to us automatically. Now, let us see how to work with RediSearch.
Step 1:
First, we need to create an index with its required specifications. This will be used to search through our JSON objects. The syntax for this is
FT.CREATE {index}
[MAXTEXTFIELDS] [TEMPORARY {seconds}] [NOOFFSETS] [NOHL] [NOFIELDS] [NOFREQS]
[STOPWORDS {num} {stopword} ...]
SCHEMA {field} [TEXT [NOSTEM] [WEIGHT {weight}] [PHONETIC {matcher}] | NUMERIC | GEO | TAG [SEPARATOR {sep}] ] [SORTABLE][NOINDEX] ...
One key role of indexes is to enable secondary query and full-text indexing and hence unlock the rich search capabilities of our Redis. Other interesting features include:
- boolean queries
- document ranking
- aggregation etc.
In our case, we can create an index to query our employee object by executing the command:
FT.CREATE idx:employee
SCHEMA
name TEXT
role TEXT
skills TAG
 We can check the list of all existing indexes on our Redis to make sure that our index was created successfully by running the command:
We can check the list of all existing indexes on our Redis to make sure that our index was created successfully by running the command:
FT._LIST

Awesome! Our created index "idx:employee" exists and we can move to the next step to add records to this index that we just created.
Step 2:
Now that we have an existing index, we can add our Redis records to it. Redis gives us the option of using various data structures like hashes and JSON. We will be modeling our documents as a JSON object in order to fully utilize the power of RedisJSON and improve the overall performance of our Redis data.
To add a document to an index, use the Redis syntax:
FT.ADD {index} {docId} {score}
[NOSAVE]
[REPLACE [PARTIAL]]
[LANGUAGE {language}]
[PAYLOAD {payload}]
[IF {condition}]
FIELDS {field} {value} [{field} {value}...]
In our case, we should run the command:
FT.ADD idx:employee employee1 1.0
FIELDS
name "Kenneth O."
role "FrontEnd Developer"
skills '["JavaScript", "ReactJs", "React Native"]'
 Looking at our command above, the key parts are:
'id:employee' - this is the name that we have chosen for the index
'employee1' - a name for the document that we want to add.
'1.0' - a score point for the document
Looking at our command above, the key parts are:
'id:employee' - this is the name that we have chosen for the index
'employee1' - a name for the document that we want to add.
'1.0' - a score point for the document
Let us add more documents.
FT.ADD idx:employee employee2 1.0
FIELDS
name "John Doe"
role "Project Engineer"
skills '["Agile Development", "TDD", "SCRUM"]'
FT.ADD idx:employee employee2 1.0
FIELDS
name "Anna David"
role "Backend Developer"
skills '["JavaScript", "NodeJs", "Express"]'
Step 3:
At this point, we can perform a query or search operation on our index. The syntax for querying an index in Redis follows the pattern shown below.
FT.SEARCH {index} {query} [NOCONTENT] [VERBATIM] [NOSTOPWORDS] [WITHSCORES] [WITHPAYLOADS] [WITHSORTKEYS]
[FILTER {numeric_field} {min} {max}] ...
[GEOFILTER {geo_field} {lon} {lat} {raius} m|km|mi|ft]
[INKEYS {num} {key} ... ]
[INFIELDS {num} {field} ... ]
[RETURN {num} {field} ... ]
[SUMMARIZE [FIELDS {num} {field} ... ] [FRAGS {num}] [LEN {fragsize}] [SEPARATOR {separator}]]
[HIGHLIGHT [FIELDS {num} {field} ... ] [TAGS {open} {close}]]
[SLOP {slop}] [INORDER]
[LANGUAGE {language}]
[EXPANDER {expander}]
[SCORER {scorer}]
[PAYLOAD {payload}]
[SORTBY {field} [ASC|DESC]]
[LIMIT offset num]
The above command can be shortened to:
FT.SEARCH i*ndex* *query*
Using our created index, let's find out all the documents that contain the word 'Developer'
FT.SEARCH idx:employee 'Developer'
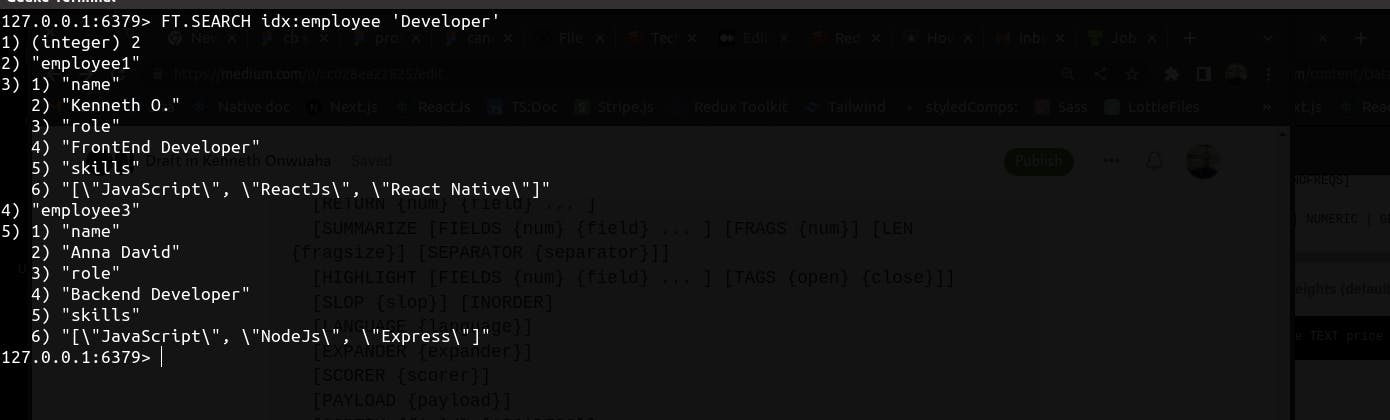
The query returns to us two documents that satisfy the query conditions. From the snippet above, 'employee1' and 'employee3' both have Developer in their role field.
We can also narrow down a query to a specific field on the documents by using the "@" character before the field name as shown below.
FT.SEARCH idx:employee '@name:John Doe'
In the above command, we are instructing our index to search through the records and return to us the document(s) where the name field has a value of 'John Doe'. The result shows that there is only one such document, 'employee3' To explore other possible RediSearch commands and features, you may want to check their official documentation below.
At this point, we have seen how to create and store a Redis JSON object using RedisJSON. We have also looked at an efficient way of indexing and querying our stored documents with RediSearch. But that is not all that Redis has to offer to us.
The Redis Enterprise is another great feature offered by Redis. It is a very versatile and efficient in-memory NoSQL database service. While it offers enterprise-grade capabilities, the high performance and simplicity of Redis are still preserved. Some of the top capabilities available on the Redis Enterprise platform include
- Full control, deploy anywhere
- Availability rate of 99.999%
- Built-in durability
- Globally distributed
- Optimized TCO
- Enterprise-grade support at all time
- The sub-millisecond speed at an infinite scale
All these features of Redis Enterprise and the ones we have looked at earlier guarantee a highly cost-efficient, performant, and scalable application.
This post is in collaboration with Redis.
To Learn More:
Watch this video on the benefits of Redis Cloud over other Redis providers
Redis Developer Hub - tools, guides, and tutorials about Redis